Data Agents Need Context Graphs. Can Your Data Pipelines Cater?
Hint: Decision Traces Are Just Events

Part 3 in the series • January 2026
Nishant Sharma — Technical Director, RudderStack. Founding engineer of RudderStack Profiles.
Disclaimer: The views expressed here are personal opinions and not necessarily endorsed by RudderStack.
📚 Series Navigation
Part 1: is_incremental() → Microbatch → this.DeRef(): Why Data Pipelines Break
Part 2: Limits of the Semantic Layer: What AI Agents Actually Need
Part 3: Data Agents Need Context Graphs. Can Your Data Pipelines Serve?(this article)
Part 4B: From Semantic Layer to Semantic Intent Compiler (next)
Part 5: Five Hard Problems Every Semantic Intent Compiler Must Solve (coming soon)
Part 6: Solving Problem 1 (coming soon)
Part 7: Solving Problem 2 (coming soon)
Part 8: Solving Problem 3 (coming soon)
Part 9: Solving Problem 4 (coming soon)
Part 10: Solving Problem 5 (coming soon)
⚡ TL;DR
In Part 2 of this series (January 2026), I argued that semantic layers pose three problems for Data Agents — incrementality, governance, determinism. That post struck a nerve — 62K+ reached the conversation.
Now the discourse has moved to “Context Graphs.” Foundation Capital calls it a trillion-dollar opportunity. Jessica Talisman says we need ontologies. Everyone agrees: AI agents need richer context than metric definitions.
But I kept asking: How will agents actually USE that context to act safely?
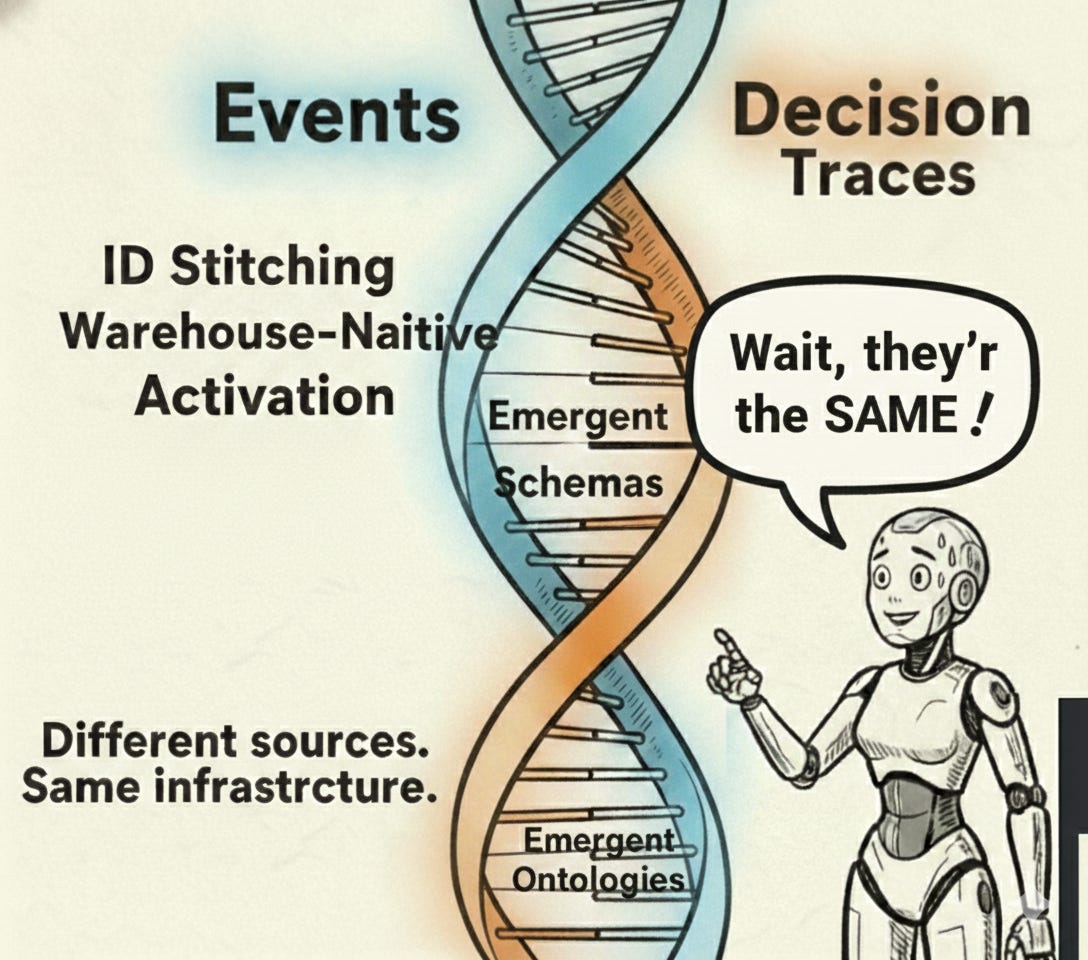
Then it clicked: Decision traces are just events. They need the same treatment we already know — emergent ontologies (just like event schemas), ID stitching, warehousing, governance, activation. The infrastructure exists. The extension is natural.
The gap: Raw facts in a warehouse are just “expensive audit logs.” To turn context graphs into agentic infrastructure, you need the Semantic Intent Compiler.
The punchline: Context graphs are the fuel. The Semantic Intent Compiler is the engine.
📖 New to this space? Quick Glossary
Data Agent — An AI system that autonomously queries, transforms, and acts on data in your warehouse or databases.
Data Pipeline (ELT) — A workflow that extracts data from sources, loads it into a warehouse, and transforms it there. Modern ELT pipelines (dbt, Airflow, Dagster) are the focus of this article.
Context Graph — A knowledge graph that captures decision traces: the exceptions, approvals, precedents, and reasoning behind business decisions. [Foundation Capital]
Knowledge Graph — A structured representation of entities and their relationships, stored as subject-predicate-object triples. [Wikipedia]
Ontology — A formal specification of concepts and relationships in a domain. Defines what things are and how they relate — enabling machines to reason, not just query. [W3C OWL]
Decision Trace — A record of why something happened: “VP approved 25% discount, citing precedent X, under policy v3.2.”
Semantic Layer — A metadata layer (dbt, LookML, Cube) that defines metrics and dimensions for consistent calculations across BI tools.
Semantic Intent Compiler — An architecture where agents output structured intent (YAML), and a compiler transforms it into incremental, governed, deterministic SQL. [Part 2 of this series]
Entity Resolution / ID Stitching — Stitching fragmented identifiers across systems to recognize the same real-world entity. “VP Jane” in a Slack thread →
Person:jane_123in your graph. [Wikipedia]Incremental Computation — Processing only what changed since the last run, rather than recomputing everything.
I. The Discourse (January 2026)
Something shifted in the data/AI conversation this month.
The thesis emerging from Foundation Capital [1]: the next trillion-dollar platforms won’t be systems of record. They’ll be systems that capture decision traces — the exceptions, approvals, precedents, and reasoning buried in Slack threads, email chains, and approval workflows.
[1]: “Decision traces capture what happened in this specific case — we used X definition, under policy v3.2, with a VP exception, based on precedent Z, and here’s what we changed.” — Foundation Capital
Jessica Talisman [2] argues that semantic layers (dbt, LookML) are just metric governance, not real semantics. AI needs ontologies: formal knowledge representation with inference rules.
[2]: “Semantic layers are built for analysis, helping humans consume data through BI tools. Ontologies are built for reasoning, helping systems and AI understand domains well enough to disambiguate data, discover context, make inferences, and support decisions.” — Jessica Talisman, Metadata Weekly
The consensus is forming: AI agents need richer context — decision traces, knowledge graphs, ontologies. Not just metric definitions.
I agree. But I kept coming back to a question I haven’t seen answered:
Context is input. How do agents ACT on that context safely?
The discourse focuses on what agents should consume. Nobody’s talking about what agents should produce — and how to make that production safe at scale.
II. The Insight: Decision Traces Are Just Events
Here’s what reframes the whole conversation.
Decision traces are just events.
Context graphs are built from decision traces — the exceptions, approvals, precedents, and reasoning buried in Slack, Notion, and email.
Different sources. Same nature as the behavioral events we’ve been tracking for a decade.
The data industry has spent 15 years building infrastructure to handle behavioral events — clicks, page views, purchases, feature usage. We’ve solved:
Ingestion: Capture events from across the org at scale
Schema Discovery: Event schemas emerge organically as products evolve
ID Stitching: Resolve fragmented identities (user_id, email, anonymous_id)
Warehousing: Land events with governance and compliance
Activation: Sync processed data to edge systems (CRM, marketing, product)
Decision traces — exceptions, approvals, precedents — need the exact same treatment. The patterns are proven. The extension is natural.
III. The DNA They Share
Decision traces and behavioral events share the same DNA. Here’s why that matters:
1. Emergent Schemas & Ontologies
Behavioral events aren’t designed in a lab. They’re discovered in the wild.
When your product team ships a new feature, new event types appear: feature_x_engaged, feature_x_upgraded. You don’t design these schemas upfront—they emerge from product evolution. Your event infrastructure adapts.
Decision traces work the same way.
When an LLM extracts decision traces from Slack threads, new trace types appear: discount_approved, exception_granted, precedent_cited. The ontology of your organizational knowledge emerges organically—just as event schemas do.
The insight: We don’t need to design a trillion-dollar ontology upfront. Ontologies emerge from data — the same way event schemas do. The infrastructure to handle emergent structures already exists.
2. ID Stitching
Behavioral events need identity resolution: Which user did this action?
Decision traces need richer identity resolution:
Which customer was this decision about?
Which approver granted the exception?
Which policy version was in effect?
Which precedent was cited?
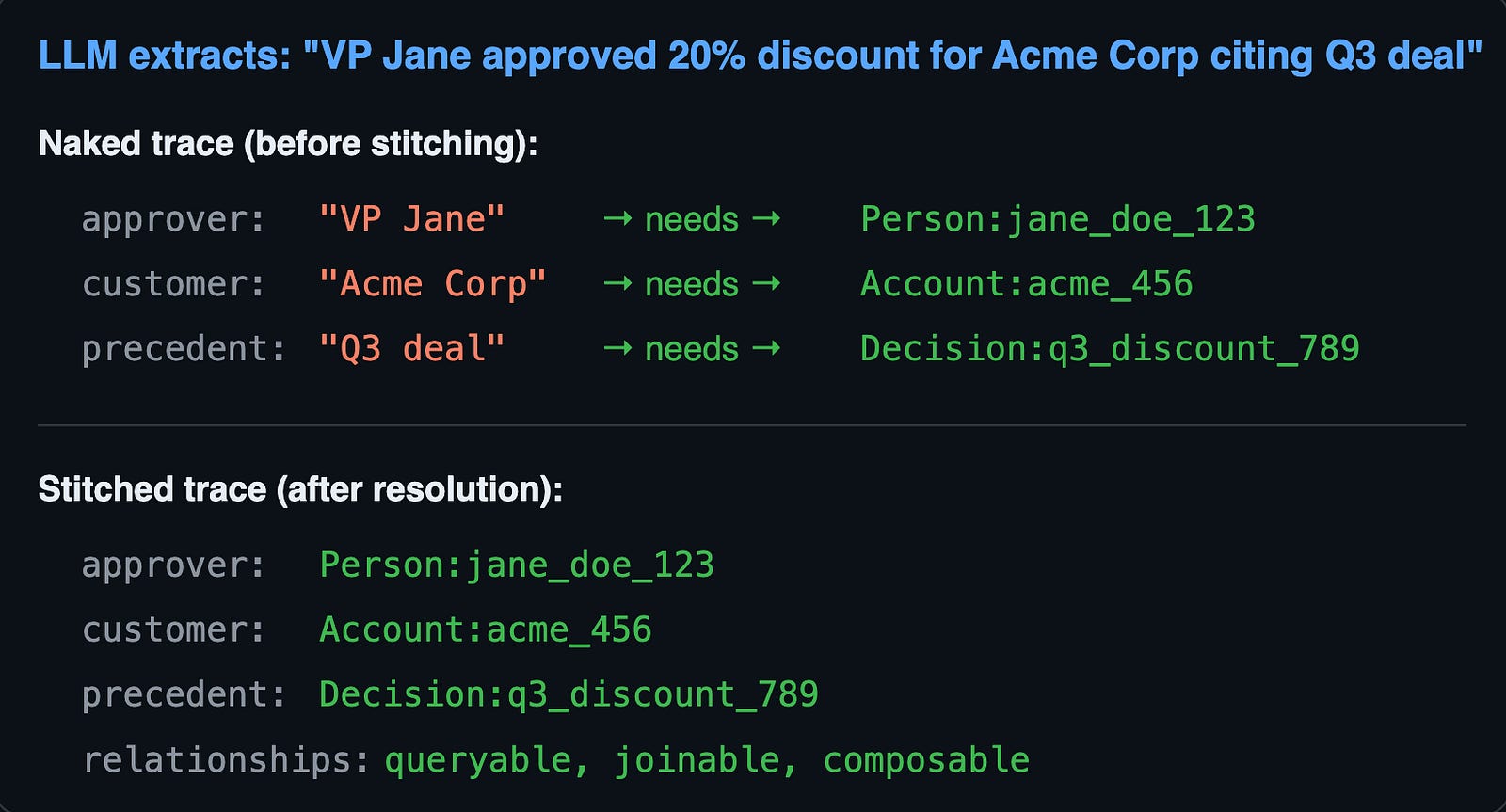
ID stitching turns naked traces into connected facts. Without it, decision traces are just text. With it, they become a queryable graph.
The steelman: “ID stitching for behavioral events is solved — deterministic keys like email, device_id, cookie. But ‘VP Jane’ in a Slack thread? That’s entity extraction, disambiguation, confidence scoring. You’re hand-waving the hardest part.”
The response: Fair. Stitching “intent” from messy threads is harder than stitching a cookie ID. But probabilistic ID stitching is already a thing — we resolve identities across systems with confidence scores and match thresholds daily. The Semantic Intent Compiler treats entity extraction as another transformation step in the pipeline, similar to how we transform raw clickstream into “Session” objects. Same infrastructure pattern. Harder extraction problem. But not a different architecture.
3. Warehouse-Native
Behavioral events land in the warehouse — same governance, same compliance, same processing infrastructure.
Decision traces should land there too. In the warehouse, alongside behavioral data. Not necessarily instead of a graph database — but at minimum, replicated there for governance, joins, and activation.

This is important. Decision traces aren’t a separate system. They’re another table in the same warehouse, governed by the same policies, processed by the same infrastructure.
The steelman: “Behavioral events are immutable — a click happened, done. But policies can be revoked. Approvals can be overturned. If the Compiler treats a revoked policy as a ‘past event’ rather than ‘current state,’ agents act on stale context.”
The response: The fact is immutable; the state is derived. Just as a Customer 360 isn’t a static table but a daily computation over behavioral events, an agent’s context is a daily computation over decision traces. We don’t worry about a policy change “breaking” the C360 — the change is the event, the active policy is derived state. The Compiler tracks both: when the fact happened (event time) and what’s true now (current state). This is bi-temporal modeling — solved infrastructure.
What about graph databases? The knowledge graph community often gravitates toward specialized graph stores (Neo4j, RDF triple stores). There’s a case for native graph traversal. But for enterprise activation — where traces need to join with behavioral data, respect the same governance, and feed the same downstream systems — warehouse-native storage has natural affinity. Vectors can live in the warehouse too. The question isn’t “graph DB vs. warehouse” but “what needs to join with what?”
What about privacy? Decision traces contain sensitive information — who approved what, internal reasoning, exceptions. This isn’t a new problem. Your warehouse already has PII detection, consent management, retention policies, and audit trails. Warehouse-native traces inherit all of it. No need to rebuild privacy infrastructure in a separate store.
What about cost and latency? Processing every Slack thread in real-time sounds expensive. It is — if you try to do it that way. But event infrastructure already solved this: incremental updates, not full reprocessing. The Compiler doesn’t re-extract every trace on every run. It processes deltas. High-signal sources (approval workflows, formal exceptions) get priority; low-signal noise gets batched. Same pattern as behavioral events. Not a new problem.
4. Feed Activation
Behavioral events are inert until they drive action — synced to CRM, triggering campaigns, personalizing product experiences.
Decision traces are the same. Traces are inert until they feed an action at the edge.
A context graph sitting in the warehouse is just an audit log. Value comes when agents can:
Update CRM based on computed risk scores (derived from traces)
Route exceptions to the right approver based on precedent
Trigger campaigns for customers matching historical patterns
Personalize products using decision context
This is activation — the same pattern the data industry uses for behavioral data, extended to decision traces.
🚪 Exit Ramp #1
The story so far: Decision traces are just events. They share the same DNA — emergent ontologies (just like event schemas), ID stitching, warehouse-native, activation-driven. The infrastructure exists. The extension is natural.
Short on time? → Jump to The Bottom Line | Subscribe for Part 4
Want the execution layer? → Continue below for the Semantic Intent Compiler
IV. The Gap: Raw Facts Are Inert
Here’s the gap in the current discourse.
The emerging consensus [1][2][3][4]: capture decision traces, build context graphs, add ontologies for AI to reason over.
All right about input. None address output.
Raw facts in a warehouse are just “expensive audit logs.”
If the agent outputs raw SQL against the warehouse — even a warehouse rich with decision traces and ontological structure — you still lose the three things my last post identified:
Incrementality: No memory of what was computed yesterday. Full recompute every time.
Governance: Knowing the policy exists doesn’t enforce it. The agent can still query what it shouldn’t.
Determinism: Same context, different day, different SQL. Fine for exploration. Not for infrastructure.
The Cost of Probability
There’s a difference between querying and acting.
For queries (dashboards, exploration): 95% accuracy is useful.
For actions (update CRM, trigger campaign, route exception): 95% accuracy is 100% failure.
Context graphs give agents the knowledge to reason — maybe 95% correctly. But you need an execution layer that delivers 100% reliability when agents act.
An LLM can “understand” your customer’s situation by reading decision traces. But can it reliably update the right record in Salesforce without duplicating, overwriting, or corrupting data?
V. The Semantic Intent Compiler
In Part 2, I argued that semantic layers have three Achilles heels — incrementality, governance, determinism — and proposed the Semantic Intent Compiler as the missing layer. If you haven’t read it, the short version:
The Semantic Intent Compiler sits between agent and execution. Instead of agents outputting raw SQL, they output structured intent (YAML). A deterministic compiler transforms that intent into SQL with guarantees: incremental, governed, deterministic.
The same architecture applies to context graphs. Raw decision traces in a warehouse are just “expensive audit logs.” To turn them into agentic infrastructure, you need the compiler to bridge the gap:
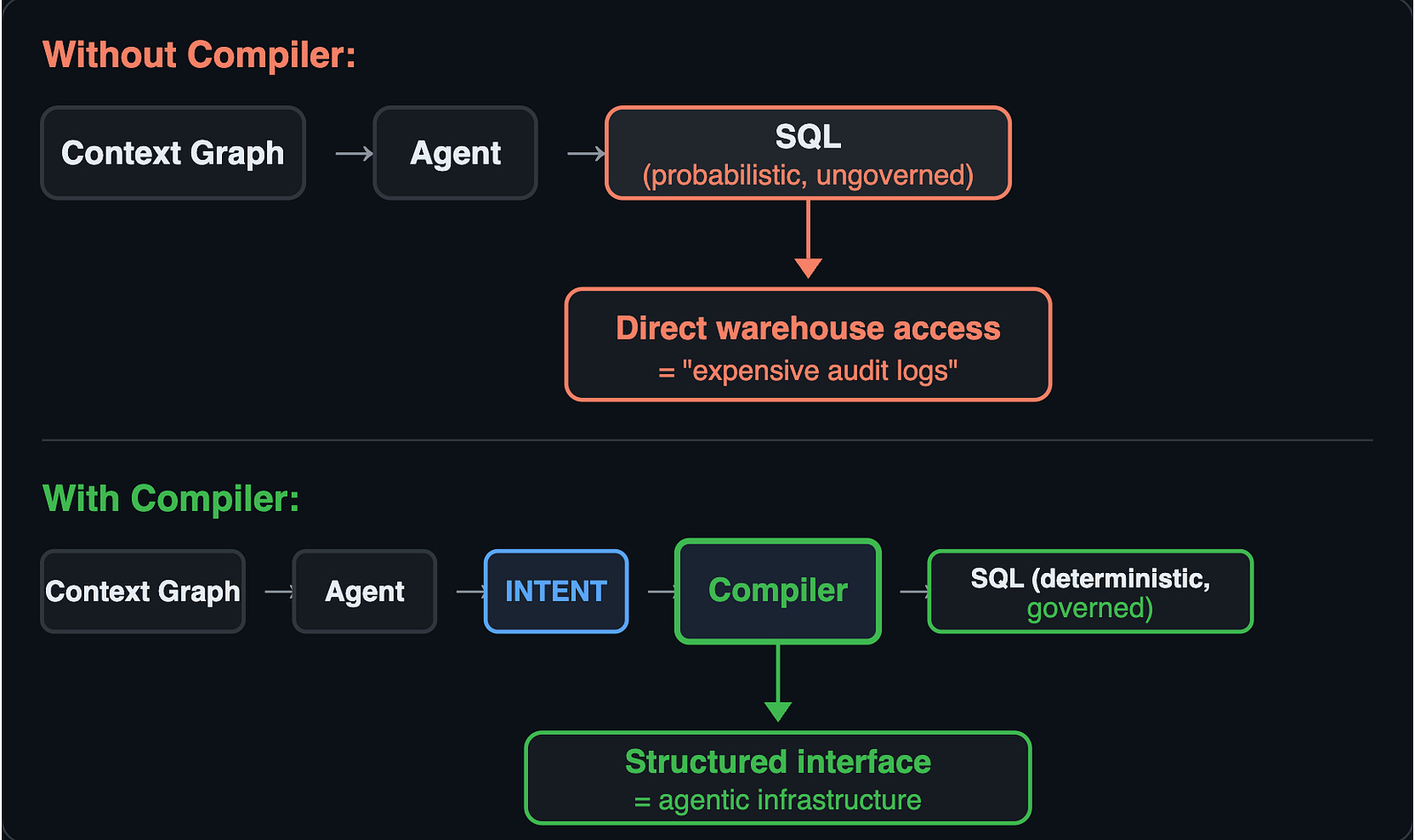
The agent doesn’t write SQL. It expresses intent — a structured declaration of what it wants computed. The compiler transforms that intent into execution with the same three guarantees:
Incremental: Don’t reprocess the entire knowledge graph for every query. Only compute what changed.
Governed: The Ontology declares the meaning; the Compiler enforces the boundary before the Agent acts.
Deterministic: Same intent + same facts = same execution. Every time.
What Intent Looks Like (Extended for Decision Traces)
Here’s the scenario the context graph crowd cares about: An agent receives a discount request that exceeds policy limits. It needs to find relevant precedents, identify the right approver, and route with full context attached.
# Agent expresses intent (not SQL):
- intent: route_exception
exception_type: discount_override
# The request context
context:
customer: Account:acme_456
requested_discount: 25%
policy_limit: 15%
customer_segment: enterprise_expansion
# Find the right approver using decision traces
find_approver:
criteria:
- has_authority: discount_exceptions > requested_discount
- has_precedent: similar_customer_segment
- recency: approved_similar_exception < 90_days
# Attach relevant precedents for the approver
include_context:
- traces.similar_precedents (top 3, same segment)
- traces.approver_history (this customer)
- traces.policy_exceptions (this quarter)
- policy.current_version
# Governance constraints
governance:
- require: audit_trail
- require: approval_chain_verified
- notify: compliance_team_if > 20%Notice what’s happening: the agent is querying the context graph (find precedents, find approver history), reasoning over ontological relationships (approver → authority → policy), and routing with full decision context. But it never writes SQL. The compiler handles the graph traversal, the joins, the incremental updates to the audit trail.
The agent declares what it wants. The compiler handles how — and guarantees governance.
The Three Achilles Heels — Addressed
Incrementality
Without Compiler: Full recompute every query
With Compiler: Only recompute what changed
Governance
Without Compiler: Policies are suggestions
With Compiler: Policies enforced at compile time
Determinism
Without Compiler: Same prompt → different SQL
With Compiler: Same intent → same SQL, always
The steelman: “Jessica Talisman argues for formal ontologies to prevent reasoning errors. If you treat traces purely as ‘events in a stream,’ you bypass the structural rigor required for safe machine reasoning. Ontologies should govern the data, not emerge from it.”
The response: Ontologies shouldn’t be handcuffs; they should be outcomes. By treating decision traces as events, we allow formal ontologies to emerge from actual organizational behavior — the same way event schemas emerge from product evolution. But emergence doesn’t mean ungoverned.
Crucially, the Compiler is a plugin architecture. It’s not the Compiler’s job to know how to avoid reasoning errors — that’s the job of the ontology plugin. The Compiler orchestrates transformation steps; the ontology plugin validates emergent structures against formal constraints (schema validation, constraint propagation, inference rules). Separation of concerns. Bottom-up discovery + top-down validation. The rigor moves from the storage layer to a dedicated transformation step.
VI. The Feedback Loop
Here’s where context graphs become a living system, not a static artifact.
Every agent action creates new decision traces:
Agent approved discount →
trace.discount_approvedemittedAgent routed exception →
trace.exception_routedemittedAgent updated profile →
trace.profile_updatedemitted
These traces flow back into the warehouse. They get ID-stitched to existing entities. They become available for future queries.
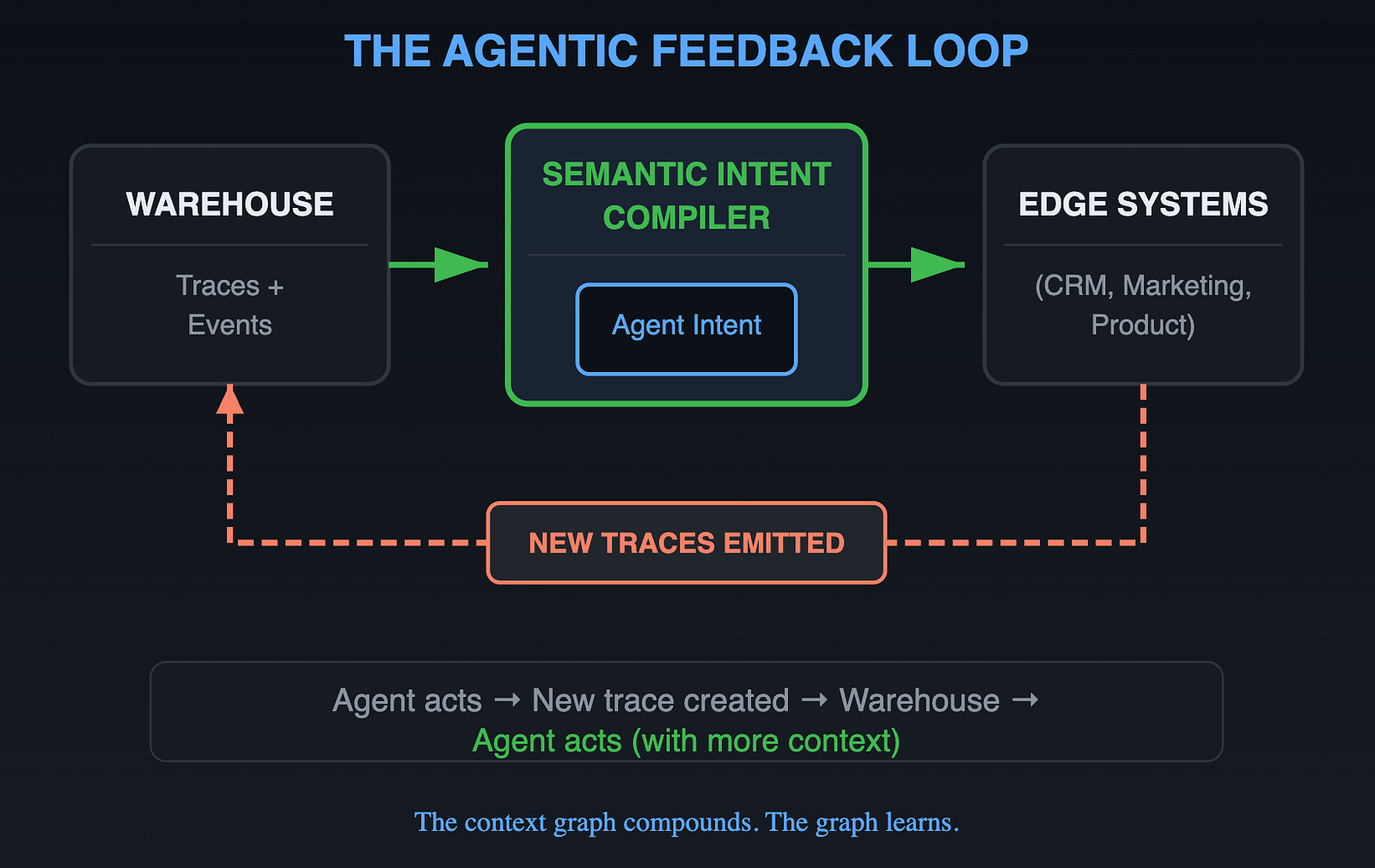
The context graph compounds. Every action adds context for future actions. Precedent becomes searchable. Exceptions become patterns. The graph learns.
VII. Open Questions
This architecture raises questions I don’t have clean answers to:
How do ontological constraints propagate to the compiler? If the ontology says “discounts require manager approval,” how does that become a compile-time check?
What’s the right authoring surface for agents? Should agents express intent in YAML? Natural language that compiles to YAML? Something else?
How much can LLMs discover vs. humans curate? Trace extraction is noisy. What’s the right human-in-the-loop for promoting raw traces to canonical facts?
Where does inference live? Jessica argues ontologies enable inference. Does that happen in the graph, the compiler, or both?
I don’t think these are solved. But I think they’re the right questions — better than “should we use knowledge graphs or semantic layers?”
What about conflicting traces? Two VPs grant contradictory exceptions in different channels. Which one wins? This isn’t a compiler problem — it’s how the world works. Humans change their minds. Policies get overridden. The system’s job is to capture each trace as it happens (immutable facts) and generate diffs when state changes. Conflict resolution rules live in the ontology plugin, not the compiler. The compiler orchestrates; the domain logic decides.
The Bottom Line
Decision traces are just events. They share the same DNA — emergent ontologies (just like event schemas), ID stitching, warehouse-native, activation-driven. The infrastructure exists. The extension is natural.
The discourse is focused on input. The emerging consensus [1][2][3][4]: capture decision traces, build context graphs, add ontologies. All right about what agents need to consume. None address what agents should produce — and how to make that production safe.
Raw facts in a warehouse are just “expensive audit logs” You can’t point an agent at a billion decision traces and hope for the best. You need a translation layer.
The Semantic Intent Compiler is the missing layer. It sits between agent and execution. Agent expresses intent. Compiler guarantees: incremental, governed, deterministic.
Context graphs are the fuel. The Semantic Intent Compiler is the engine.
📖 Learn More
Explore the RudderStack Profiles Documentation to see a Semantic Intent Compiler in action — features, identity resolution, and this.DeRef().
📚 Series Navigation
← Part 1: is_incremental() → Microbatch → this.DeRef(): Why Data Pipelines Break
← Part 2: Limits of the Semantic Layer: What AI Agents Actually Need
Part 3: Decision Traces Are Just Events (this article)
Part 4: Coming soon → Inside the Compiler: How Semantic Intent Becomes Incremental SQL
References
Jaya Gupta & Ashu Garg. “AI’s Trillion-Dollar Opportunity: Context Graphs.” Foundation Capital, December 2025.
Jessica Talisman. “Ontologies, Context Graphs, and Semantic Layers: What AI Actually Needs in 2026.” Metadata Weekly, January 2026.
Jessica Talisman. “Context Graphs and Process Knowledge.” LinkedIn, January 2026.
Prukalpa Sankar. “Investment Thesis: Asset Catalog Graphs as the Enduring Moat in Agentic Data/AI Governance.” LinkedIn, January 2026.
André Lindenberg. “How Do Context Graphs and Knowledge Graphs Differ From Each Other?” LinkedIn, January 2026.
Shirshanka Das. “Decision Traces Are Only as Good as the Context That Fed Them.” LinkedIn, January 2026.
© Nishant Sharma 2026